Entwicklung eines Prototypen#
Eine wichtige Voraussetzung für die Anwendung und Verbreitung einer Technologie ist deren Einfachheit, überschaubare Kosten und ein unbestrittener Mehrwert für den Verwender bzw. das die Technologie einsetzende Unternehmen. Im Falle des Betriebs von Large Language Models in einer On-Premises-Umgebung bedeutet das, ein verfügbares, entsprechend trainiertes Sprachmodell mit überschaubarem Aufwand auf verfügbarer bzw. vergleichsweise leicht beschaffbarer Hardware lauffähig zu bekommen und anschließend dauerhaft und nachhaltig lauffähig zu halten.
Mit dem im Folgenden vorgestellten Prototypen soll die Machbarkeit eines solchen Systems demonstriert werden.
Analyse mit Pflichtenheft#
Ausgangspunkt und Zielstellung für die Entwicklung dieses Prototypen war die Anforderung, die Produktpalette eines Unternehmens mit Hilfe eines intelligenten Chatbots erfahrbar zu machen. Das betreffende Unternehmen ist eine Molkerei mit Sitz in Süddeutschland und vielen weiteren Produktions- und Vertriebsstandorten weltweit. Die Produktpalette umfasst nicht allein klassische Molkereiprodukte, sondern darüber hinaus auch diverse Milchauszüge mit einem breiten industriellen Anwendungsbereich, wie Pharma, Gastgewerbe und Nahrungs- und Genussmittel.
Die Vielzahl der Produkte, Produktvarianten und Anwendungsbereiche macht es Anwendern, Technikern und Einkäufern bisweilen nicht leicht, die richtige Auswahl zu treffen. Künstliche Intelligenz bzw. deren Anwendung in Form von großen Sprachmodellen soll diesen Auswahlprozess künftig erleichtern. Die zu entwickelnde Anwendung geht dabei über eine reine Suchfunktion hinaus. Vielmehr erfolgt die Eingrenzung von passenden Produkten und deren Varianten im Rahmen eines maschinell gestützten Dialogprozesses. Ein Chatbot liefert dafür eine geeignete Anwendung.
Design / Architektur / Algorithmen#
Die Anwendung basiert auf einem on-premises gehosteten Sprachmodell. Dieses verarbeitet die Nutzereingaben und übersetzt sie in Tasks, die anschließend von geeigneten Werkzeugen verarbeitet werden. Das Domänenwissen des Sprachmodells ist begrenzt. Das Wissen erschließt sich das Modell erst zum Zeitpunkt der Ausführung durch Integration in einen Prozess der Wissensanreicherung — ein Konzept namens Retrieval-Augmented Generation (RAG).
Im Rahmen der Anwendungsentwicklung kommt ein klassisches Client-Server-Modell zum Einsatz. Teile der Anwendung, wie die Programmlogik, die verwendeten Sprachmodelle und für den Betrieb erforderliche Datenbanken, werden als Dienste bereitgestellt. Auf diese Dienste kann per Commandline Interface (CLI), in einer späteren Ausbaustufe ggfs. auch per Web-Interface oder per API zugegriffen werden.
Der Prototyp wurde mit Python entwickelt. Die Programmiersprache Python hat sich bei der schnellen Entwicklung und insbesondere in primär datengetriebenen Anwendungsszenarien bewährt. Die Sprache hat zudem die nötige Reife, eine große Entwicklergemeinschaft und verfügt über ein umfassendes Ökosystem an performanten Erweiterungen für den Bereich des maschinellen Lernens.
Zwei Erweiterungen seien hervorgehoben:
- Ollama — eine Lösung für das vereinfachte Hosting von lokalen Sprachmodellen.
- LangChain — ein in Python und JavaScript geschriebenes Framework, das eine Vielzahl von bereits fertig entwickelten Funktionen und Integrationen für einen beschleunigten Entwicklungsprozess liefert.
Komponenten der Anwendung#
Die prototypische Anwendung umfasst verschiedene Komponenten zur Datenerfassung, -verarbeitung und -speicherung, sowie die Interfaces für Nutzereingaben, die Agenten für die Auswertung des Kontexts und die Anreicherung des Ausgabeergebnisses per Chatfunktion.
Der Aufbau der Anwendung umfasst die folgenden Komponenten:
| Komponente | Beschreibung |
|---|---|
| Reader | Methoden zum Einlesen von verschiedenen Datenquellen |
| Splitter / Data Cleaner | Methoden zur qualitativen Aufbereitung der Eingabedaten |
| Embedder | Modul zur Vektorisierung von ausgewählten Daten |
| Datenbank Manager | Speicherung der Daten |
| Retriever | Tools zur Datenabfrage |
| Agents / Generator | Methoden zur Konfiguration von KI-Agenten und deren Ausgaben |
| CLI | Möglichkeit zur Ausführung des Programms auf der Konsole |
| Jupyter Notebooks (REPL) | Einfache Möglichkeit zur schrittweisen Programmausführung und Tests |
| Web-Interface, API (optional) | Module zur komfortablen Datenabfrage und -ausgabe |
| Caching (optional) | Speicherung von Nutzereingaben und Ausgaben zur Verbesserung des Nutzungskontexts |
Aufbau der Anwendung#
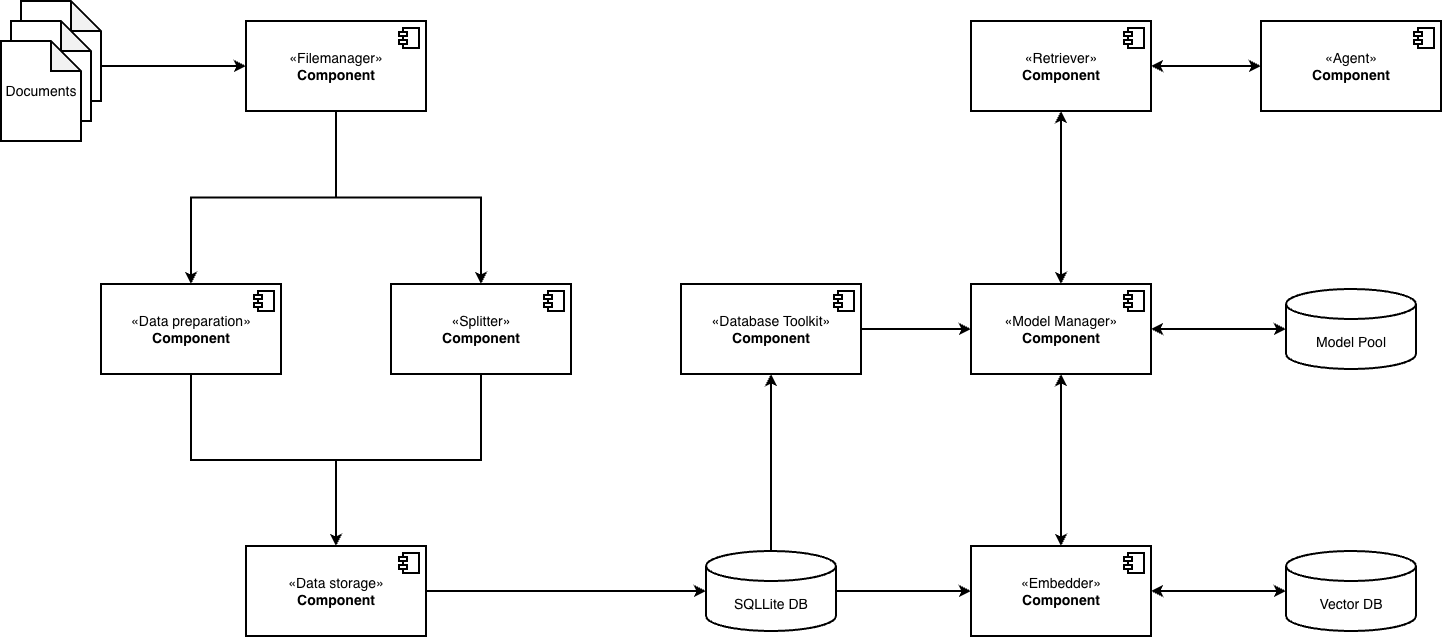 Das Komponentendiagramm der Anwendung zeigt den Datenfluss.
Das Komponentendiagramm der Anwendung zeigt den Datenfluss.
Implementierung#
Die Implementierung erfolgte bislang in einem iterativen Prozess, bestehend aus Anforderungsdefinition, testgetriebenem Coding, Bewertung und Restrukturierung. Hierbei wurden verschiedene Anwendungsfälle separat entwickelt und anschließend abstrahiert und in Module ausgegliedert.
Herausforderungen#
Eine besondere Herausforderung bei der Entwicklung des Prototypen bestand und besteht in der Auswahl eines geeigneten Sprachmodells unter Berücksichtigung des konkreten Anwendungsfalls und der zur Verfügung stehenden Hardware.
Eine steile Lernkurve brachte auch die vorgelagerte Analyse und Aufbereitung der Daten für deren spätere Abfrage mit sich. Insbesondere das Zusammenspiel von verwendetem Sprachmodell, dessen Konfiguration sowie geeigneten Prompts haben einen entscheidenden Einfluss auf das zu erwartende Ergebnis. Bei der Auswahl von Produkten aus einer Datenbank muss das Sprachmodell in die Lage versetzt werden, sprachbasierte Nutzereingaben in Structured Query Language (SQL) zu übersetzen und dabei das spezifische Datenbankschema berücksichtigen.
Für das Finetuning sind umfangreiche Tests nötig. Dafür sollten die Antwortnachrichten des Sprachmodells dokumentiert und permanent analysiert werden.
Entwicklung und Test#
Der Prototyp wurde auf einem handelsüblichen Laptop entwickelt. Bei der Auswahl wurde besonderes Augenmerk auf die Verfügbarkeit von Grafikleistung und Arbeitsspeicher gelegt.
Testumgebung#
| Hardware | Apple MacBook Air M3, 24 GB RAM, > 128 GB SSD |
| Betriebssystem | macOS 15.7 (Sequoia) |
| Software | Python 3.13 inkl. LangChain, SQLAlchemy, Pandas, Qdrant; Ollama; ggfs. Docker |
Bei dem Versuchsaufbau handelt es sich primär um eine Machbarkeitsstudie. Der Anwendungsfall ist vergleichsweise überschaubar und unter Verwendung der genannten Hardware gut und in annehmbarer Zeit nutzbar. Auf umfassende Testreihen zur Ermittlung und Optimierung des Setups und der Rechenleistung wurde im Zusammenhang mit dieser Arbeit verzichtet.
Installations- und Benutzeranleitung#
Der Code für den entwickelten Prototypen steht als Repository bei GitHub zur Verfügung:
github.com/andreasrieger/on-prem-llms
Systemvoraussetzungen#
- Python 3: python.org/downloads
- Ollama: ollama.com/download
- Kommandozeileninterpreter: Bash, Terminal oder Windows-Shell
- Alternativ / Optional: JupyterLab oder Jupyter Notebook zur Ausführung der Notebooks
Installation und Ausführung#
- Öffnen Sie Terminal oder ein vergleichbares Kommandozeilentool
- Wechseln Sie in ein Verzeichnis, in welches das Repository kopiert werden soll
- Repository klonen:
git clone https://github.com/andreasrieger/on-prem-llms.git - In das erstellte Verzeichnis wechseln:
cd on-prem-llms - Abhängigkeiten installieren:
pip install -r requirements.txt - Lokales Package installieren:
pip install --editable . - Programm starten:oder
python3 rag_agent.pypython3 sql_agent.py
Alternativ öffnen Sie das Verzeichnis mit einer IDE, die Jupyter Notebooks ausführen kann, und führen das Notebook im Verzeichnis notebooks/ aus.
 Ausschnitt: Retrieval + Antwortgenerierung vom SQL‑Agenten
Ausschnitt: Retrieval + Antwortgenerierung vom SQL‑Agenten
Zusammenfassung#
On‑Premises‑LLMs sind — mit Einschränkungen — praxistauglich und mit überschaubarem Aufwand realisierbar. Das nötige Domänenwissen erhalten die Modelle durch die Einbindung von bereitgestellten Wissensquellen (RAG). Die Leistungsfähigkeit des Systems steht und fällt dabei mit sauber aufbereiteten Daten, der Auswahl eines passenden Sprachmodells und einer passenden Systemkonfiguration. Der Prototyp belegt die Machbarkeit auf handelsüblicher Hardware, macht aber zugleich deutlich, dass die Produktionsreife weitere Investitionen, eine sorgfältige Planung, Monitoring und fortwährende Tests erfordert.